Motivation
In zahlreichen Unternehmen sind die IT-Landschaften mit den zugehörigen Architekturkomponenten in den letzten Jahrzehnten sukzessive erweitert und ergänzt worden. Einmal getroffene und langfristig bindende Investitionsentscheidungen haben dazu geführt, dass eine stetige Anreicherung vorhandener Datenbanken und Anwendungssysteme um Inhalte und Funktionalitäten erfolgte, häufig ohne nicht mehr benötigte Komponenten abzuschalten oder zu löschen. Zudem entstand oftmals teils aus Partikularinteressen einzelner Abteilungen, teils aufgrund nicht abgestimmter oder durchgesetzter Strategien ein Flickenteppich unterschiedlicher Systembestandteile zuzüglich der erforderlichen Schnittstellen.
Abbildung 1 illustriert exemplarische die Systemlandschaft zahlreicher mittelgroßer und großer Organisationen und erweist sich als tendenziell eher stark unter- als übertreibend. Insbesondere bei Konzernen dürfte sich die Anzahl an Einzelkomponenten mit großer Wahrscheinlichkeit im Bereich von einigen Dutzend oder mehr bewegen mit einer entsprechenden Anzahl an Schnittstellen. Durchaus kritisch muss gewertet, dass selbst eine derart grobe Übersicht über die Architekturlandschaft vielerorts gar nicht existiert und demzufolge keine Transparenz über Datenaustauschbeziehungen und -flüsse vorhanden ist. Wenn jedoch davon ausgegangen werden kann, dass deren Pflege und Wartung einen nicht unerheblichen Anteil an der Arbeitsbelastung der zuständigen Mitarbeiter hat, erweist sich dieser Zustand als höchst unerfreulich.

Abbildung 1: Komponenten und Datenflüsse in größeren Organisationen (in Anlehnung an: Thomson/Jain 2013)
Einordnung und Abgrenzung
An dieser Stelle setzt das Konzept der Data Lineage an, das verspricht, eine größtmögliche Transparenz in das Verknüpfungsgefüge und Abhängigkeitsnetz der einzelnen Datenobjekte zu bringen. Dass sich dieses Unterfangen als durchaus nicht trivial erweist, belegt ein detaillierterer Blick auf einzelne Komponenten. So greifen große Unternehmen beispielsweise für die Aufbereitung der Daten zu Reporting- und Analysezwecken heute auf das ELT-Konzept zurück. Dies bedeutet, dass die Daten zunächst in die Data-Warehouse-Datenbank geladen werden (z.B. in eine Staging Area), um von dort aus durch datenbankeigene Mechanismen wie Views oder Skripte (etwa im Rahmen von Stored Procedures oder durch eigene Skriptsprachen wie BTEQ beim Anbieter Teradata) auf mehreren Stufen weiter bedarfsgerecht verarbeitet zu werden. Naturgemäß entwickeln sich derartige Views und Skripte im Laufe der Zeit immer weiter zu komplexen Gebilden, die in hunderten von Zeilen Qualitätssicherungs-, Verknüpfungs- und Harmonisierungslogiken in sich tragen.
Doch dies ist nur eine der Herausforderungen, denen sich Data-Lineage-Werkzeuge stellen müssen. Insbesondere in heterogenen Umgebungen, in denen Softwareprodukte unterschiedlichster Hersteller zum Einsatz gelangen, fällt die Zuordnung von Verknüpfungen zwischen den Datenobjekten zumeist schwer. Zwar weisen zahlreiche Produkte eigenen Komponenten zur Verwaltung von Metadaten auf (z. B. Data Dictionaries in Datenbanksystemen), allerdings unterscheiden sich die zugrunde liegenden Prinzipien und technologischen Umsetzungen teils erheblich. Auch hier müssen die erfolgreichen Lineage-Werkzeuge Integrationslösungen anbieten.
Bevor jedoch weiter auf die einzelnen erforderlichen Funktionalitäten eingegangen wird, ist zunächst die Begriffsbedeutung näher zu spezifizieren. Zur Begrifflichkeit Data Lineage existieren unterschiedliche inhaltliche Vorstellungen. Eine erste wörtliche Übersetzung von Lineage führt zu „Abstammung“, wobei hier zumeist der familiäre Stammbaum gemeint ist. Dagegen bezeichnet Data Lineage die Datenherkunft und geht mit der Fragestellung einher, woher aufbereitete Daten stammen (Risch et al. 2009). Dazu wird der Datenfluss rückwärtsgerichtet als Prozess der Verarbeitung von Daten möglichst umfangreich abgebildet, im Idealfall von der Datenverwendung beim Informationskonsumenten bis zurück zum Ort der Datenentstehung. Eine derartige End-to-end Lineage dokumentiert als Herkunftsnachweis, wo und wie die Daten auf diesem Wege gespeichert, transformiert und kombiniert werden und dies automatisch über System- und Organisationsgrenzen hinweg möglichst bis zur ursprünglichen Datenerfassung.
Auch die entgegengesetzte Sichtweise von der Datenentstehung bis zur Datenverwendung erweist sich als interessant und wird häufig als Impact Analysis bezeichnet. Diese Untersuchung beleuchtet, in welchen nachfolgenden Prozessen und Stufen Ausgangsdaten Verwendung finden und lässt sich somit als Verwendungsnachweis verstehen. Einen guten Überblick über im Unternehmen existierenden Datenflüsse liefert eine Visualisierung als gerichteter Graph (vgl. Mosley/Brackett/Earley et al. (2009), S. 20; Thomson/Jain (2013)).
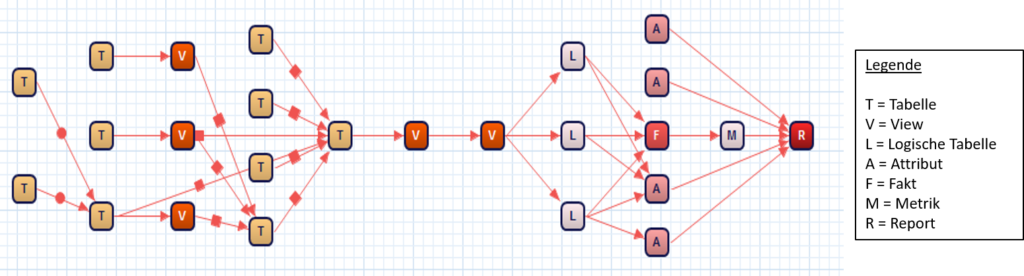
Abbildung 2: Exemplarische Visualisierung von Datenflüssen (Quelle: www.metabi.de)
Für bestimmte Aufgabenstellungen erweist es sich als unerlässlich, eine detailliertere Darstellung der Abhängigkeiten bis auf die Feldebene zu erzeugen. Unterschieden werden kann hierbei zwischen direkten Abhängigkeiten zwischen einzelnen Feldern, bei denen eine direkte Zuordnung zwischen Ausgangs- in ein Zieldatenobjekt existiert, und indirekten Abhängigkeiten, bei denen beispielsweise ein Feld als Filter in eine „Where“-Klausel eingeht.

Abbildung 3: Visualisierung von Abhängigkeiten auf Feldebene (Quelle: www.metabi.de)
Einsatzbereiche und Nutzenpotenziale
Data Lineage und Impact Analysen lassen sich für unterschiedliche Einsatzszenarien sinnvoll nutzen. Zunächst erzeugen die zugehörigen Werkzeuge eine umfassende technische Dokumentation der relevanten Objektabhängigkeiten und Datenflüsse. Vor allem im Zusammenspiel mit Komponenten, die heute als Datenkatalog (Data Catalog) bezeichnet werden und sich wachsender Aufmerksamkeit in den Unternehmen erfreuen, gelingt hierdurch eine integrierte Abbildung aller Systemmetadaten und dies nicht nur für die verwendeten Speicherkomponenten, sondern darüber hinaus auch für Verarbeitungs- und Aufbereitungsbausteine (z. B. ETL-Strecken) sowie Endbenutzer-Tools (beispielsweise für das Reporting). Voraussetzung hierfür sind selbstverständlich Software-Lösungen, die systemübergreifend die Metadaten automatisch sammeln und integrieren.
Häufig haben in größeren Unternehmen die Endanwender Fragen zu einzelnen Ausgabegrößen wie Kennzahlenausprägungen oder zweifeln gar deren Korrektheit an. In diesem Fall helfen Lineage-Tools dabei, schnell den kompletten Durchlauf einzelner Datenobjekte durch die Systemwelt nachzuvollziehen. Insbesondere in komplexen Systemumgebungen mit zahlreichen Verarbeitungsstufen lassen sich so rasch die beteiligten Einzelobjekte identifizieren und näher untersuchen.
Auch können sich Veränderungen an den Quellsystemen einstellen, die von Modifikationen der Datentypen einzelner Felder bis zu ganzen Systemablösungen reichen. Hier dient die Impact Analyse dazu, Auswirkungen aufzuzeigen und benötigte Anpassungen bei nachgelagerten Stufen durchzuführen.
Schließlich sind es vor allem in großen Data-Warehouse-Umgebungen die häufig als Housekeeping bezeichnen Arbeiten, die wirksam unterstützt werden. Beispielsweise lassen sich mit den Werkzeugen leicht Verzweigungsäste im Verarbeitungsbaum identifizieren, die im Berichtswesen nicht weiter verwendet werden (z. B. Datenbanktabellen oder Views ohne Nachfolger) und möglicherweise löschbar sind. Ebenso erfolgt die Identifikation von Abfragen, die nicht mehr funktionieren, weil sie auf Tabellen zugreifen, die zwischenzeitlich verändert wurden.
Nutzergruppen
Als primäre Nutzergruppe kommen zunächst die Mitarbeiter in einem Business Intelligence Competence Center in Betracht, deren Aufgabe u. a. darin besteht, die täglich anfallenden Änderungswünsche umzusetzen sowie Fragen zu beantworten und Probleme zu beheben. Darüber hinaus wird vor allem die Einarbeitung neuer Kollegen in diesem Bereich drastisch erleichtert.
Bei geeigneter Visualisierung der Metadatenstrukturen und -flüsse in einer leicht zugänglichen Benutzungsoberfläche (z. B. einem Wiki) stellen die Tools darüber hinaus auch geeignete Hilfsmittel für die Mitarbeiter aus Fachabteilungen zur Verfügung. Anreichern lässt sich die automatisch generierte Dokumentation dann beispielsweise durch manuell erfasste fachliche Definitionen der relevanten Objekte sowie durch die Angabe von Verantwortlichkeiten und Zuständigkeiten.
Eine weitere Nutzergruppe stellen die Mitarbeiter und Verantwortlichen aus dem Bereich Datenqualität dar. Die Werkzeuge helfen hier bei der Identifikation von Datenqualitätsproblemen bis zu deren Ursprung. In diesem Kontext sind auch die Auditierer zu nennen, deren Aufgabe u. a. in der Überprüfung der Systemqualität liegt.
Fazit
Data-Lineage-Werkzeuge bieten heute wertvolle Hilfestellungen bei der Schaffung von Transparenz in komplexen Systemumgebungen und können darüber hinaus zu erheblichen Kosteneinsparungen durch den Wegfall zeitintensiver Suchvorgänge führen. Zudem unterstützen sie bei der Einhaltung regulatorischer Vorgaben, wie beispielsweise der Datenschutzgrundverordnung (DSGVO) oder im Bankenbereich vor allem bei der Umsetzung der“Principles for effective risk data aggregation and risk reporting” (BCBS 239).
Literatur
Mosley, M.; Brackett, M. H.; Earley, S.; Henderson, D. (2009): The DAMA guide to the data management body of knowledge (DAMA-DMBOK guide). Bradley Beach, N.J.: Technics Publications LLC.
Risch, T.; Canli, T.; Khokhar, A.; Yang, J.; Munagala, K.; Silberstein, A. (2009): Data Provenance. In: L. Liu & M. T. Özsu (Eds.), Encyclopedia of Database Systems, p. 608, Boston, MA: Springer US.
Thomson, B.; Jain, S. (2013): Data Lineage. An Important First Step for Data Governance. Verfügbar unter http://www.b-eye-network.com/view/17023, Abruf am 29.05.2020.